Mar 23, 2020
种草指南|2020深度学习GPU横向比较,哪款是你的心头好?
搞AI,谁又能没有“GPU之惑”?下面列出了一些适合进行深度学习模型训练的GPU,并将它们进行了横向比较,一起来看看吧!
微信ID:kuanfankeji

CPU是一个有多种功能的优秀领导者。它的优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。
下图是处理器内部结构图:

DRAM即动态随机存取存储器,是常见的系统内存。
Cache存储器:电脑中作为高速缓冲存储器,是位于CPU和主存储器DRAM之间,规模较小,但速度很高的存储器。
算术逻辑单元ALU是能实现多组算术运算和逻辑运算的组合逻辑电路。
当需要对大数据bigdata做同样的事情时,GPU更合适,当需要对同一数据做很多事情时,CPU正好合适。

GPU能做什么?关于图形方面的以及大型矩阵运算,如机器学习算法等方面,GPU就能大显身手。
简而言之,CPU擅长统领全局等复杂操作,GPU擅长对大数据进行简单重复操作。CPU是从事复杂脑力劳动的教授,而GPU是进行大量并行计算的体力劳动者。

深度学习是模拟人脑神经系统而建立的数学网络模型,这个模型的最大特点是,需要大数据来训练。因此,对电脑处理器的要求,就是需要大量的并行的重复计算,GPU正好有这个专长,时势造英雄,因此,GPU就出山担当重任了。
RTX 8000:48GB VRAM,约5500美元 RTX 6000:24GB VRAM,约4000美元 Titan RTX:24GB VRAM,约2500美元
RTX 2080 Ti:11GB VRAM,约1150美元 GTX 1080 Ti:11GB VRAM,返厂翻新机约800美元 RTX 2080:8GB VRAM,约720美元 RTX 2070:8GB VRAM,约500美元
RTX 2060:6GB VRAM,约359美元。
RTX 2060(6 GB):你想在业余时间探索深度学习。 RTX 2070或2080(8 GB):你在认真研究深度学习,但GPU预算只有600-800美元。8 GB的VRAM适用于大多数模型。 RTX 2080 Ti(11 GB):你在认真研究深度学习并且您的GPU预算约为1,200美元。RTX 2080 Ti比RTX 2080快大约40%。 Titan RTX和Quadro RTX 6000(24 GB):你正在广泛使用现代模型,但却没有足够买下RTX 8000的预算。 Quadro RTX 8000(48 GB):你要么是想投资未来,要么是在研究2020年最新最酷炫的模型。 NV TESLA V100 (32GB):如果你需要在NVIDIA数据中心使用CUDA,那么TESLA就是必选品了。
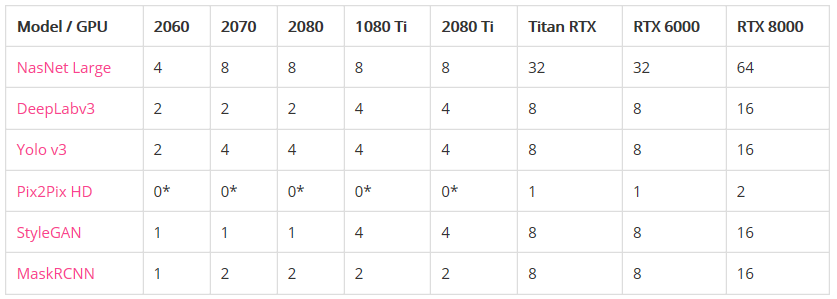
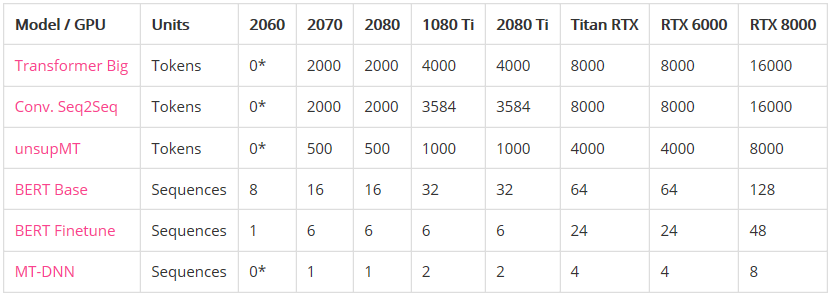
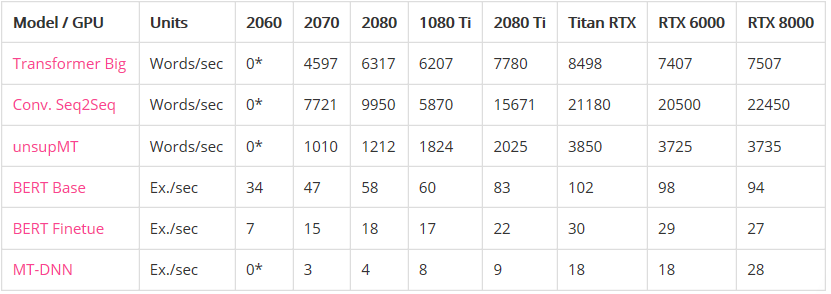
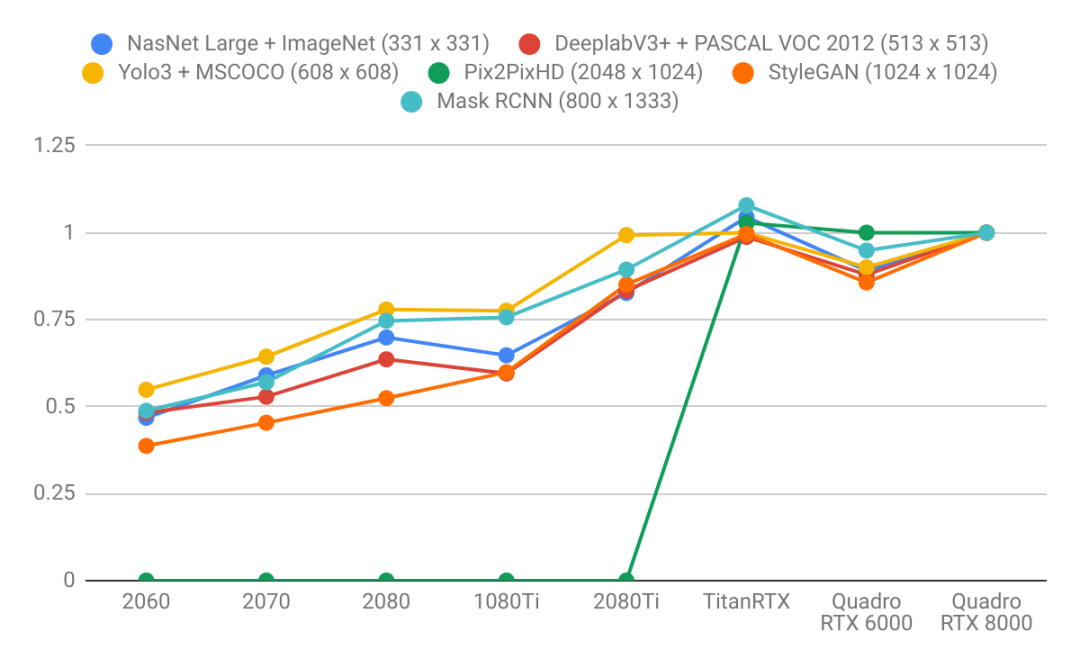
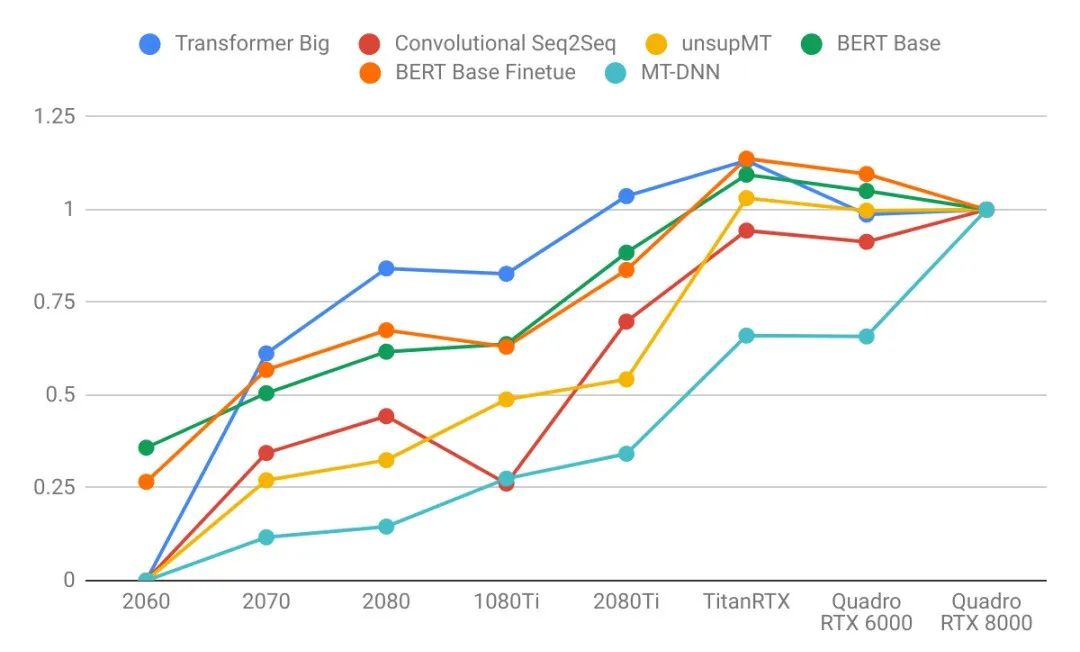
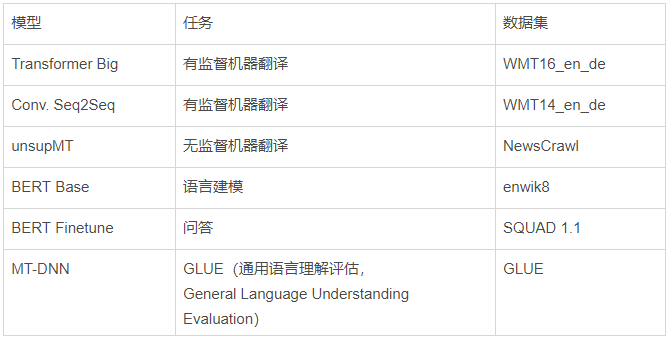
语言模型比图像模型受益于更大的GPU内存。注意右图的曲线比左图更陡。这表明语言模型受内存大小限制更大,而图像模型受计算力限制更大。 具有较大VRAM的GPU具有更好的性能,因为使用较大的批处理大小有助于使CUDA内核饱和。 具有更高VRAM的GPU可按比例实现更大的批处理大小。只懂小学数学的人都知道这很合理:拥有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU容纳3倍大的批次。 比起其他模型来说,长序列语言模型不成比例地占用大量的内存,因为注意力(attention)是序列长度的二次项。

深度学习客户 免费体验
云轩云计算管理 零等待
云轩Cloudhin专注Deep learning和高性能计算服务器定制,针对主要深度学习框架(如TensorFlow、Caffe 2、Theano或Torch)进行了优化和设置,在桌面上即可提供强大的深度学习功能。布局全国八家直属分公司,实时响应您的定制需求,做您服务器的贴心管家。