【热点资讯】闻其声而知其人——语音识别技术的革命
那我们今天就来聊聊,语音聊天中最重要的技术——语音识别。
未见其人先闻其声,要想了解语音识别这个概念,先要看看下面这段对话。
“我来迟了,不曾迎接远客!”
“这些人个个皆敛声屏气,恭肃严整如此,这来者系谁,这样放诞无礼?”
“一定是凤辣子来了。”
看过《红楼梦》的朋友,想必都对这段对话印象深刻,贾母正是通过声音的音色来辨别来者何人,这就叫“闻其声而知其人”。语音识别大概就是这个意思了。

通俗的说就是,我说,他听。
专业的说,语音识别技术(AutomaticSpeech Recognition)的目标是将人类的语音表达的词汇内容转换为计算机可读的输入内容,例如按键、二进制编码或者字符序列。
语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译。
语音识别技术所涉及的领域就更加广泛了,包括信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等各类行业领域。
其实对于一款社交软件来说,可以说语音功能决定了一切。大多数用户都是从文字聊天流向语音聊天的,尽管现在大部分的聊天还是通过文字表达的手段,但是如果说这款社交软件缺失了语音聊天语音识别的功能,我想它一定很快就被淘汰了。
而输入法软件更是必不可少的内嵌了语音输入的功能,通过语音识别技术,通过识别语音内容形成文字输出。想来语音识别技术发展到今天,已经是一项不可或缺的功能。
其实早在上世纪50年代就有人开始研究这项技术了,直到80年代才取得重大突破。之后这项技术便从实验室开始走向整个市场。
目前语音识别是市场上应用最为成熟的人机交互方式,苹果的Siri、微软的Cortana都运用了这项技术原理。

那么在AI行业中
语音识别技术又有怎样的发展呢?
“语音识别”的终极梦想,是真正能够理解人类语言甚至是方言环境的系统。但几十年来,人们并没有一个有效的策略来创建这样一个系统,直到人工智能技术的爆发。
在过去几年中,人们在人工智能和深度学习领域的突破,让语音识别的探索跨了一大步。市面上玲琅满目的产品也反映了这种飞跃式发展,例如亚马逊Echo、苹果Siri等等。
多年来,理解人类一直都是人工智能的最重要任务之一。人们不仅希望机器能够理解他们在说些什么,还希望它们能够理解他们所要表达的意思,并基于这些信息采取特定的行动。而这一目标正是对话式人工智能(AI)的精髓。
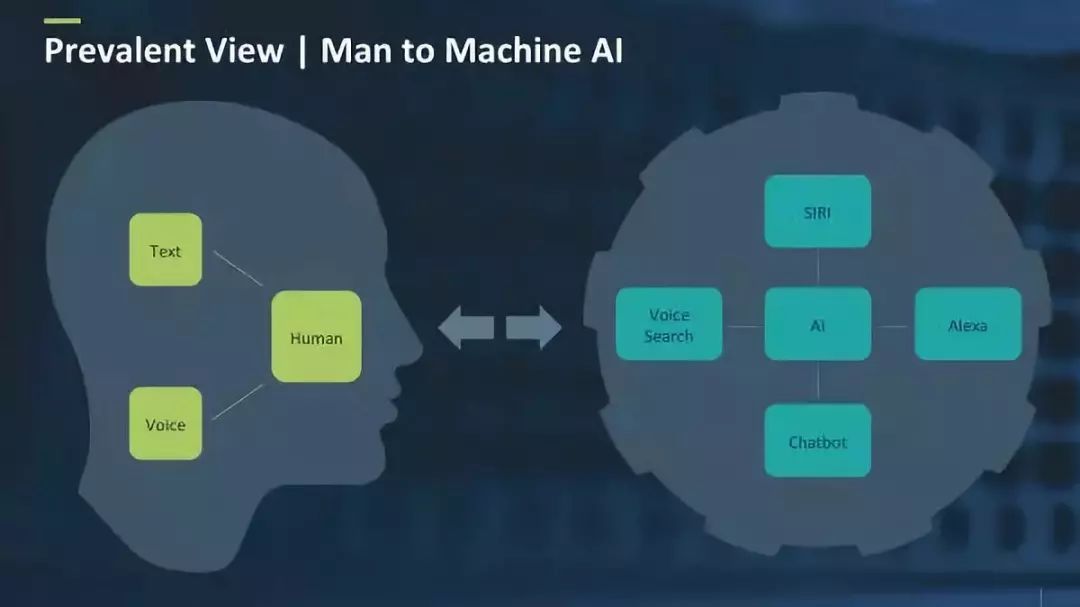
对话式AI包含有两个主要类别:人机界面,以及人与人沟通的界面。在人机界面中,人类与机器往往通过语音或文本交互,届时机器会理解人类(尽管这种理解方式是有限的)并采取相应的一些措施。
而人工智能所包含的机器感知和机器识别在对话式AI中被这样体现出来:所有的语音分析技术,如识别和性能分析被机器感知所控制;所有与语言理解能力相关的技术则被机器识别所包含(自然语言处理也包含在内)。
早年语音识别技术的发展缓慢,缺陷就在于建立的语言模型并不完善。因为语言模型和声学模型是听写识别的基础,这方面没有突破,语音识别的进展就只能是一句空话。而口音也是语音识别的技术难点,尽管就目前所知道的语言库中,各地方言词汇库在不断地扩充,而微信也加入了识别方言的功能,但这还远远不够,语音识别的自适应能力仍需要进一步的加强。
简单地说,目前使用的声学模型和语音模型太过于局限,以至用户只能使用特定语音进行特定词汇的识别。如果突然从中文转为英文,或者法文、俄文,计算机就会不知如何反应,而给出一堆不知所云的句子;或者用户偶尔使用了某个专门领域的专业术语,如“信噪比"等,可能也会得到奇怪的反应。这一方面是由于模型的局限,另一方面也受限于硬件资源。
随着两方面的技术的进步,将来的语音和声学模型可能会做到将多种语言混合纳入,用户因此就可以不必在语种之间来回切换。此外,对于声学模型的进一步改进,以及以语义学为基础的语言模型的改进,也能帮助用户尽可能少或不受词汇的影响,从而可实行无限词汇识别。
基于深度学习对语音识别技术的改进
深入学习对语音识别领域产生了巨大的影响。其影响非常深远,即使在今天,几乎每一个语音识别领域的解决方案都可能包含有一个或多个基于神经模型的嵌入算法。
通常而言,人们对语音识别系统的评价都基于一个名为配电盘(SWBD)的行业标准。SWBD是一个语音语料库,整合了电话中的即兴对话,包含音频和人声的副本。
语音识别系统的评估标准主要基于其误字率(WER),误字率是指语音识别系统识别错误的单词有多少。
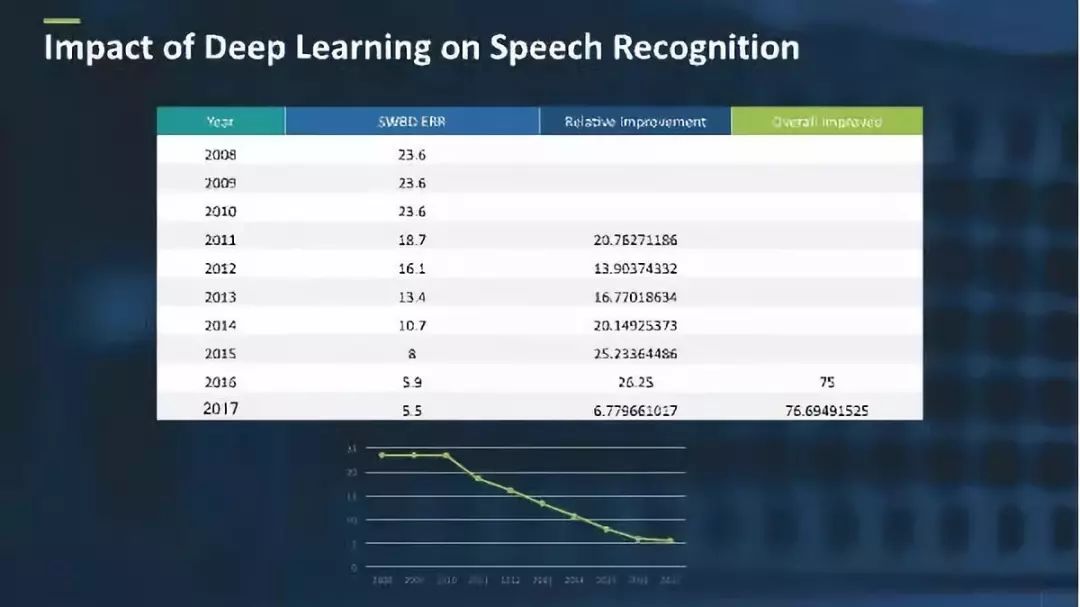
从2008年到2011年,误字率一直都处于一个稳定的状态,位于23%至24%之间;而深度学习从2011年开始出现时起,误字率从23.6%降低至5.5%。这一重大发展对语音识别开发而言是一种变革,其误字率的改进相对提高了近77%。
误字率的改善也产生了广泛应用,例如苹果Siri、亚马逊Alexa、微软Cortana 和GoogleNow,这些应用也可以通过语音识别激活各种家居,如亚马逊Echo和Google Home。

而随着亚马逊Echo与Google Home的成功,许多公司正在发布能够识别理解语音的智能扬声器和家庭设备。然而,这些设备的推出又带来了一个新问题:用户说话时往往距离麦克风不是很近,例如用户用手机对话时的状态。而处理远距离语音识别又是一个具有挑战性的问题,很多研究小组也正在积极研究这个问题。如今,创新的深度学习和信号处理技术已经可以提高语音识别的质量了。

语音识别系统的关键问题之一是缺乏现实生活的数据。例如,很难获得高质量的远程通话数据。但是,有很多来自其他来源的数据可用。一个问题是:我们可以创建合适的合成器来生成培训用的数据吗?今天,生成合成数据并培训系统正在受到重视。
为了训练语音识别系统,我们需要同时具备音频和转录的数据集。人工转录是繁琐的工作,有时会导致大量音频的问题。因此,就有了对半监督培训的积极研究,并为识别者建立了适当程度的信心。
今天,大多数语音识别系统都是基于云的,并且具有必须解决的两个具体问题:延迟和持续连接。延迟是需要立即响应的设备(如机器人)的关键问题。在长时间监听的系统中,由于带宽成本,持续连接是一个问题。因此,还需要对边缘语音识别的研究,它必须保持基于云的系统的质量。
深度学习在语音识别和对话式AI领域刻下了深深的印记。而鉴于该技术最近获得的突破,我们真的正处于一场革命的边缘。
而最大的问题在于,我们是否准备赢得语音识别领域的技术挑战,并像其他商品化技术一样开始运用它呢?或者说,是否还有另一个新的解决方案正等待着我们去发现?毕竟,语音识别的最新进展只是未来科技蓝图的一小块:语言理解本身就是一个复杂而且或许更加强大的一个领域。