RTX 30系列性能≥2倍图灵GPU!AI算力前瞻,性价比超泰坦
「无论性能还是能效,安培架构GPU都是图灵的两倍,」黄仁勋于今日凌晨的RTX 30系列线上发布会坦言。「从架构、定制流程设计、电路、逻辑、封装、series IO、显存、供电、散热、软件和算法…… 我们在所有层面压榨GPU的性能,最终实现了世界领先水平。」
今天,距离英伟达发布世界首款GPU、也是第一款以Geforce为名的显示核心——Geforce 256已经21年了。21年来,GPU彻底改变了现代计算机图形学。如今,采用NVIDIA Ampere架构的GeForce RTX 30系列GPU再次走出迈向未来的一大步。
前所未有的性能飞跃
最强旗舰级GPU问世
NVIDIA最先进的技术和二十多年的图形研发成果,使NVIDIA RTX集可编程着色、光线追踪和人工智能于一身,为全新GeForce RTX 30系列GPU和NVIDIA Ampere架构带来惊人性能,将助力开发者打造新世界。

技术突破详情:
全新的流式多处理器:全球速度最快、效率最高的GPU部件,其处理能力为30 Shader-TFLOP/s, 并且FP32吞吐量是上一代产品的2倍。
第二代RT Cores:全新专用RT Core计算能力为58 RT-TFLOPS,是上一代的2倍,同时支持光线追踪、着色与计算。
第三代Tensor Cores:全新专用Tensor Core吞吐量是上一代的2倍,能够更快速、更高效地运行AI驱动的技术,如NVIDIA DLSS,算力高达238 Tensor-TFLOPS。
NVIDIA RTX IO:实现基于GPU的快速加载和游戏资源解压,与硬盘和传统存储API相比,输入/输出性能最高可加速100倍。结合微软全新Windows版 DirectStorage API,RTX IO将几十个CPU核心的工作转移到RTX GPU上,提高帧率,并实现近乎瞬时的游戏加载。
全球最快显存:NVIDIA与镁光合作,为RTX 30系列打造全球最快的GDDR6X显存,为显卡应用提供接近1TB/s的数据传输速度,最大限度地提升游戏和应用性能。
新一代工艺技术:来自三星的全新8nm NVIDIA定制工艺,可实现更高的晶体管密度和更高的效率。

总体来说,GeForce RTX 30系列确实占据了GPU界的多项「第一」:首款有着24GB GDDR6X显存的消费级图形卡;首批支持 HDMI 2.1的GPU,一块显卡即可实现4k高刷新率或8k游戏;首批支持AV1编译码器的独立GPU,实现以更少的带宽观看更高分辨率的视频流。
RTX 30系列具体参数

GeForce RTX 3080:建议零售价¥5,499起,预计9月17日起售。GeForce RTX 3080内建8704 个CUDA,比GeForce RTX 2080快2倍。GeForce RTX 3080 拥有10GB的全新高速GDDR6X显存,运行速度高达19Gbps,在4K分辨率下带来每秒60帧稳定的游戏体验。
GeForce RTX 3070:建议零售价¥3,899起,预计9月24日起售。GeForce RTX 3070 售价仅为GeForce RTX 2080 Ti的一半不到,比GeForce RTX 2070快60%。它配备8GB GDDR6显存,有5888 个CUDA,相比之下,2080Ti的CUDA核心是4300个,所以3070性能超过 2080Ti,看来是没什么问题的。

GeForce RTX 3090:建议零售价¥11,999起,预计10月起售。GeForce RTX 3090 被称为 "性能猛兽"。它配备有一个三槽双轴,流线型设计的散热器,比TITAN RTX安静10倍,并且极致冷静,可降低GPU保持温度最高达30℃。它的24GB GDDR6X显存可以应对最具挑战性的人工智能算法,并满足大规模内容创作的需求。GeForce RTX 3090比TITAN RTX快50%,在8K分辨率下让玩家能在众多顶级游戏中达到60fps。
AI算力性能前瞻
RTX 30系列采用的都是今年 5 月刚刚推出的最新7纳米制程架构安培(Ampere),其首先被 Tesla A100所采用。RTX 3090的24G内存和1399美元的价格或许能够让很多对深度学习有需求的用户省下买泰坦的预算。
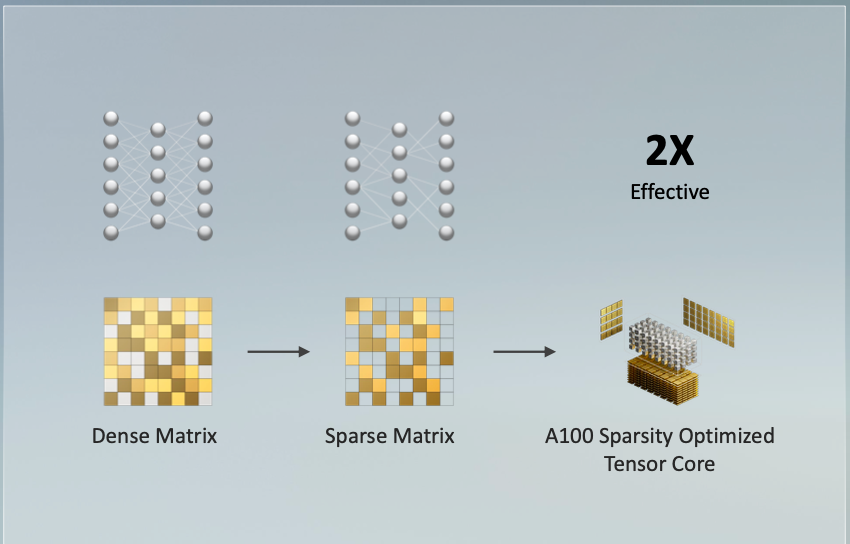
针对稀疏矩阵的加速可以让安培架构GPU处理AI任务的效率提高一倍
安培架构还有一些针对AI计算特有的机制,其中的三代Tensor Core会对稀疏张量运算进行特别加速:执行速度提高一倍,也支持TF32、FP16、BFLOAT16、INT8和INT4等精度的加速—系统会自动将数据转为TF32格式加速运算,现在你无需修改任何代码量化了,直接自动训练即可。

不过由于消费级和专业级芯片的结构不尽相同,我们不能把 Ampere A100 芯片的AI训练性能简单地直接拿来作为参考,还需要等待官方公布,以及最终实测的数据。
黄仁勋表示,GeForce RTX 30 系列显卡具备三项基础处理技术:30TFLOPS 算力的可编程着色器(Turing架构是11),双倍吞吐量,用于光追的RT Core(58 RT TFLOPS,Turing架构是34),以及可自动忽略次要DNN权重的Tensor Core(238Tensor TFLOPS,旧版为 89)。
三个方面,性能相比前一代都是翻倍。
宽泛科技携手NVIDIA
宽泛科技作为英特尔、英伟达等芯片及品牌厂商的坚实合作伙伴,NVIDIA潜力AI公司加速计划成员,携手专注为人工智能提供硬件解决方案及相关服务,已成为国内过万家企业、院校及研究机构的信息化解决方案供应商。

旗下Cloudhin®云轩支持Deep learning和高性能计算服务器定制,针对主要深度学习框架(如TensorFlow、Caffe 2、Theano或Torch)进行了优化和设置,为计算系统提供强大的深度学习功能。

NVIDIA Tesla A100(PCIE版)、RTX 30系列深度学习服务器现已开启预约定制服务,A100由NVIDIA Ampere优化软件提供支持:包括CUDA 11;50多个CUDA-X™库的新版本;多模式对话式AI服务框架NVIDIA Jarvis;深度推荐应用框架NVIDIA Merlin;RAPIDS™开源数据科学软件库套件;NVIDIA HPC SDK,其中内含编译器、库和软件工具,可最大程度地提高开发者的工作效率以及HPC应用的性能和可移植性。
凭借这些功能强大的软件工具,开发者们能够构建并加速HPC、基因组学、5G、数据科学、机器人学、深度学习等领域的应用。

专业勤修,锐意进取。云轩技术工程师毕业于NVIDIA深度学习研究所,丰富经验,值得信赖。更多定制方案请联系客服,我们将实时响应您的定制需求。
如果您有合作需求或宝贵建议,欢迎来信。
邮箱:hezuo@kuanfans.com
合作热线:400-610-1360转375899
